기본키가 아닌 모든 속성이 기본키에 완전 함수 종속된 상태를 무엇이라 하는가?
A ] 제2정규형
엔터티의 일반속성 간에는 서로 종속적이지 않는다.
A ] 제3정규형
데이터 관점 : 업무가 어떤 데이터와 관련 ? 데이터간의 관계는 ? → DB구축목적
프로세스 관점 : 무엇을 해야하는지 ?
데이터 프로세스의 상관관점 : 업무처리방법에 따라 데이터가 어떤영향 ?
정규화
제 1 정규화 : 테이블의 속성 하나는 하나의 속성값만을 가져야한다.
제 2 정규화 : 기본키중에 특정 컬럼에만 종속된 컬럼이 존재할 경우 테이블을 분해한다.
제 3 정규화 : 제 2 정규형을 만족하는 상태에서 이행함수 종속을 제거하는 과정

기본엔터티 : 기본 그 업무에 원래 존재하는 정보 타, 엔터티의
부모 역할 자신의 , 고유한 주식별자 가짐 ex) , 사원
부서
중심엔터티 : 중심 기본 엔터티로부터 발생 다른 , 엔터티와의
관계로 많은 행위 엔터티 생성 ex) , , 계약 사고 주문
행위엔터티 : 2개 이상의 부모엔터티로부터 발생 자주 ,
바뀌거나 양이 증가 ex) , 주문목록 사원변경이력
슈퍼 서브 타입 데이터 모델 변환기술
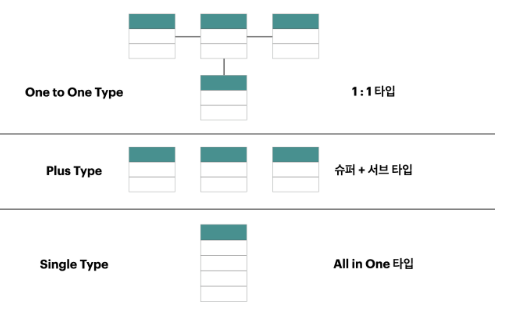
1. 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성 (OneToOne Type)
2. + 슈퍼타입 서브타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼 서브타입 + 테이블로 구성 (Plus Type)
3. 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성 (Single Type, All in One Type
그룹함수
1. null은 다찾기
2. 총합행 X -> grouping sets
총합행 O -> 행의수가 많으면 cube 적어보이면 roll up
엔터티
1. 관리해야 할 대상이 엔터티가 될 수 있다.
2. 인스턴스가 2개이상
3. 업무에서 사용해야함(프로세스)
4. 관계를 하나 이상 가져야함.
도메인
1. 데이터유형
2. 크기
3. 제약조건
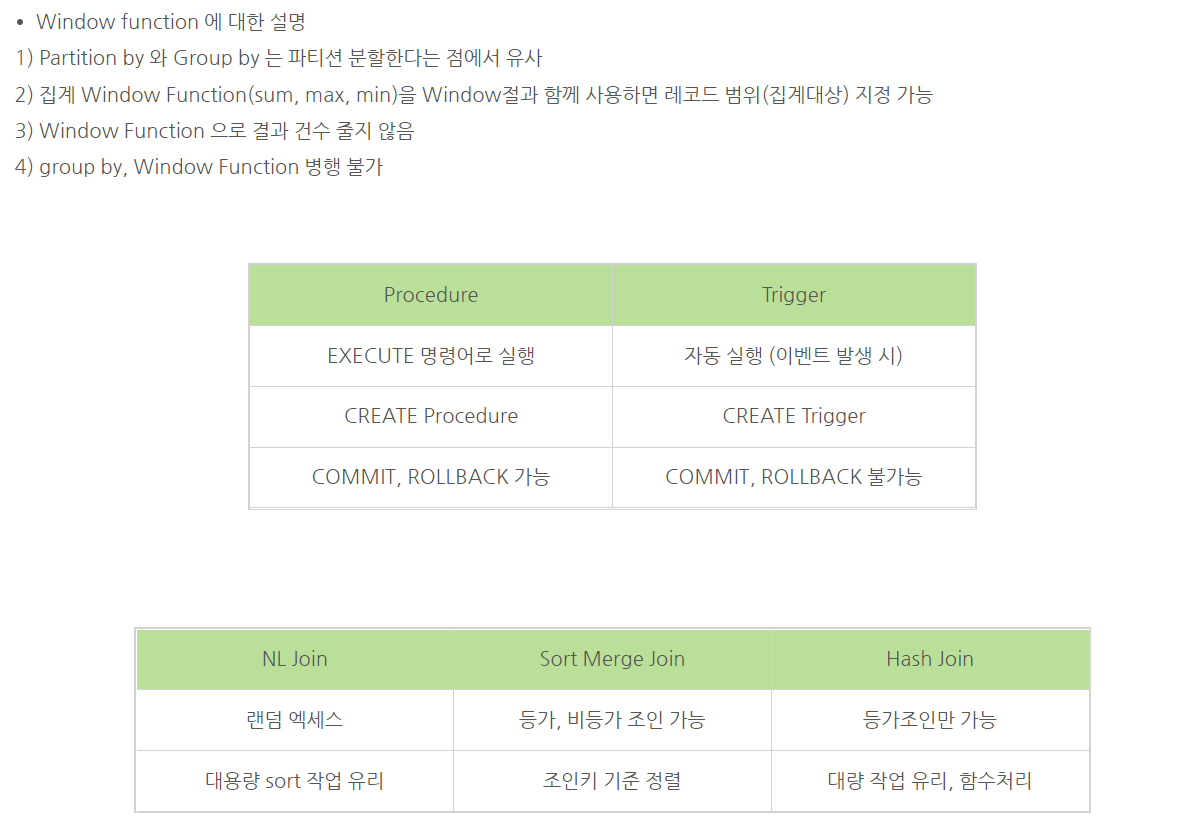
Hash Join
1. 등가 join만 사용
2. 선행 테이블이 작다
3. Hash 처리를 위한 별도 공간필요
NL join
1. 랜덤 액세스
2. 대용량 sort 작업
3. 선행테이블이 작을수록 유리
Sort Merge
1. join키를 기준으로 정렬
2. 등가/비등가 join 가능
3. 느리다
Optimizer
1. CBO : 가장 경제적인 것을 정함
2. RBO : 규칙에 의해서 정함
분산데이터베이스 장점

* 공집합일 경우 집계함수의 결과는 NULL 임
ex ] SELECT SUM(COL1) ..... WHERE 1=2 -> NULL
ex] SELECT COUNT( * ) .... WHERE 1=2 -> 0
* USING 이랑 NATURAL JOIN 에서는 ALIAS 사용 금지!!
VIEW : 논리적으로 존재하는 가상 테이블로서 물리적으로 실제 데이터를 저장하지않는다.
1. 독립성 : 테이블구조가 변경되어도 뷰를 사용하는 응용프로그램은 변경하지 않아도된다.
2. 편리성 : 복잡한 질의를 뷰로 생성해서 단순하게 작성가능
3. 보안성 : 숨기고 싶은 정보가 있으면 뷰를 생성할때 해당 컬럼을 빼고 생성하여 숨길수있다.
엔터티
독립 엔터티 : 사람 , 물건 , 장소 등과 같이 현실세계에 존재하는 엔터티
업무중심 엔터티 : 트랙젝션이 실행되면서 발생하는 엔터티
종속 엔터티 : 주로 1차 정규화로 인해 관련 중심엔터티로부터 분리된 엔터티
교차 엔터티 : M : N 의 관계를 해소하려는 목적으로 만들어진 엔터티 [ ex > M:M -> 1:M ]
서브쿼리
연관 서브쿼리 ( CORRELATED 서브쿼리 )
: 서브쿼리 내 메인쿼리 컬럼이 사용됨 -> where 절 에서만 사용가능
DB 명령어
DML ( 데이터 조작어 ) : SELECT , UPDATE , INSERT , DELETE
DDL ( 데이터 정의어 ) : CREATE , DROP , ALTER , RENAME , TRUNCATE
, MODIFY(오라클)
DCL ( 데이터 제어어 ) : GRANT , REVOKE
// GRANT ON TO( 권한부여) , REVOKE ON FROM ( 권한회수 )
TCL ( 트랜젝션 제어어 ) : COMMIT , ROLLBACK , SAVE POINT
칼럼 변경은 ALTER TABLE ~ MODIFY(수정) 문을 이용한다
추가는 ADD , 삭제는 DROP
그룹함수
ROLLUP : 소그룹간의 소계를 계산 ex] 시간 , 지역 등 Rollup 의 인수 = 계층구조
ROLLUP( A , B ) = GRUOPING SETS((A,B),A,() )
GROUPING : 집계표시면 1 , 아니면 0 ( 소계 : 합계를 표시 )
CUBE : 결합가능한 모든값에 대하여 다차원 집계를 생성
CUBE ( A , B ) = GROUPING SETS ( A , B ,( A,B ) , ())
GROUPING SETS : 인수들에 대한 개별 집계를 구할 수 있다. 다양한 소계 집합생성가능 ( 계층구조 x)
CURSOR 순서
선언 -> OPEN -> FETCH -> CLOSE
JOIN

ROUND(반올림) → ROUND(7.45, 1)이므로 함수의 첫 번째 인자값인 7.45를 소수점 첫째 자리까지 반올림
ABS(절댓값) : EX) ABS(-7.45) → 7.45
FLOOR : (CEIL의 반대, 정수로 내림)
TRUNC : (소수점 버림)
CEIL : (정수로 올림)
단일행 NULL 관련 함수 종류
NVL (표현식1,표현식2 ) / IS NULL(표현식1,표현식2 ) : 표현식1의 결과값이 NULL 이면 표현식2값을 출력한다.
NVL2 ( 표현식 , 지정된 값1 , 지정된값 2 ) : 표현식이 NULL이 아닐경우 지정된값1로 출력 , NULL경우 지정된값 2 로 출력한다.
NULL IF (표현식1 , 표현식2) : 표현식 1 이 표현식2와 같으면 NULL 을 같지않다면 표현식1값을 출력한다.
COALESCE ( 표현식1 , 표현식2 , ... ) : 임의의 개수가 표현식에서 NULL이 아닌 최초의 표현식을 나타낸다. 모든 표현식이 NULL 이면 NULL을 리턴한다.
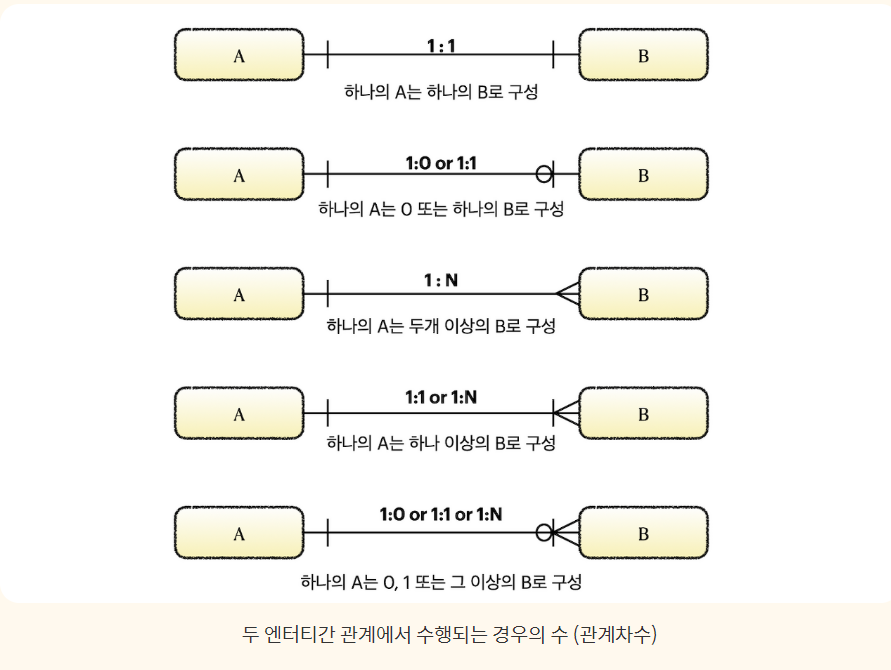
[ 관계차수 ] 두 엔터티간 관계에서 수행되는 경우의수
비교연산자 우선순위

순수 관계 연산자
종류 : SELECT , PROJECT , JOIN , DIVISION
분산데이터 장단점
장점
1. 데이터베이스 신뢰성과 가용성이높다.
2. 분산데이터베이스가 병렬처리를 수행하기때문에 빠르다.
3. 분산데이터베이스를 추가하여 시스템 용량확장이 쉽다.
단점
1. 데이터베이스가 여러 네트워크를 통해서 분리되어있어서 관리가어렵다.
2. 보안관리가 어렵다
3. 데이터 무결성 관리가 어렵다
4. 데이터베이스 설계가 복잡하다.
반정규화
- 데이터 무결성 해칠 수 있음
- 절차
1. 대량범위 처리 빈도수 좃사
2. 범위처리 빈도수
3. 통계처리 여부
테이블 병합
1:1 관계 : 1:1 관계를 통합하여 성능향상
1:M 관계 : 1:M 관계를 통합하여 성능향상
슈퍼 / 서브타입 : 슈퍼 / 서브 관계를 통합하여 성능향상
테이블 분할
수직 분할
컬럼단위의 테이블을 디스크 I/O를 분산처리하기위해 테이블을 1:1로 분리하여 성능향상
수평 분할
행 단위로 발생되는 트랙잭션을 분석하여 데이터 접근의 효율을 높혀 성능을 향상시키기위해 행 단위로 테이블을 쪼갬
테이블 추가
중복테이블 추가 :
다른업무이거나 서버가 다른경우 동일한 테이블 구조를 중복하여 원격 조인을 제거하고 성능을 향상
통계 테이블 추가 :
SUM , AVG 등을 미리 수행하여 계산해 둠으로써 조회 시 성능을 향상
이력 테이블 추가 :
이력테이블 중에서 마스터 테이블에 존재하는 레코드를 중복하여 이력 테이블에 존재하는방법
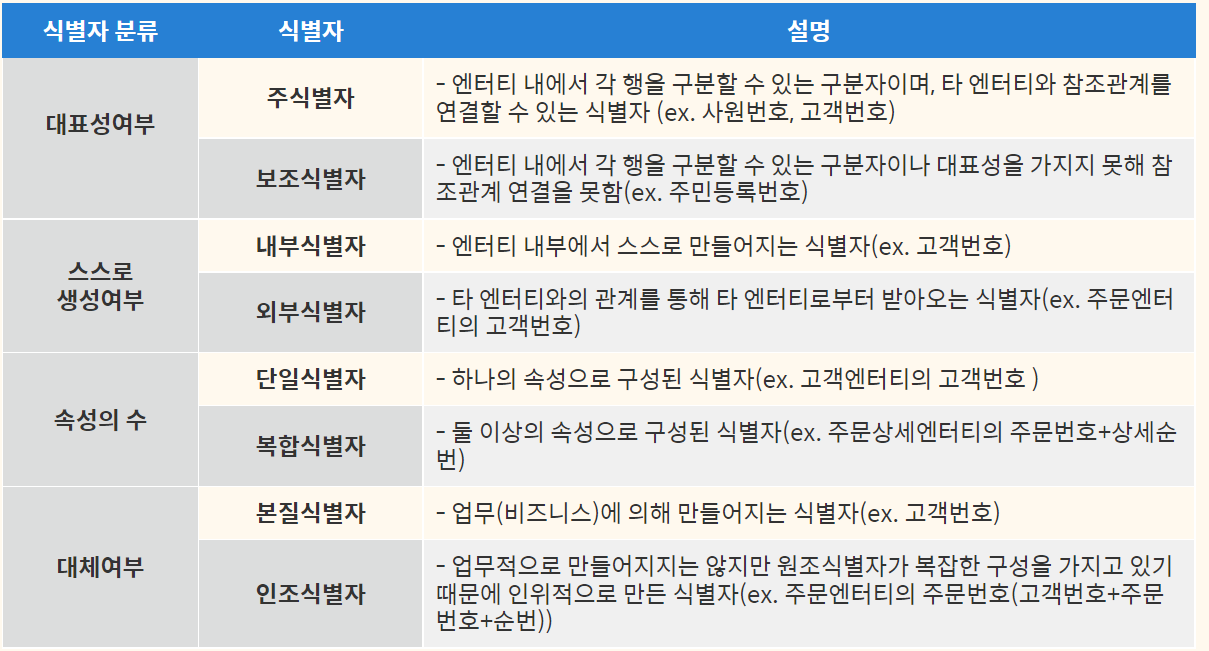
식별자
스키마
외부 스키마 : 사용자 관점
내부 스키마 : 통합 관점
개념 스키마 : 물리적관점
인덱스 특징
- 원하는 테이블을 쉽게 찾을수 있도록 돕는다.
- 테이블을 기반으로 선택적으로 생성할 수 있는 구조이다.
- 기본목적은 검색성능 최적화 이다.
- 검색조건을 만족하는 데이터를 인덱스를 효과적으로 찾을 수 있도록 돕는다.
- DML 작업은 테이블과 인덱스를 함께 변경하므로 느려지는 단점
- 인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬을 수행
주식별자의 특징 ( 유최불존 )
유일성 : 유일하게 인스턴스 구분가능
최소성 : 주식별자 속성수 = 최소
불변성 : 주식별자 값은 변경 X
존재성 : 반드시 값이 들어와야함 ( NOT NULL )
삭제 명령어 차이점
DROP : 구조까지 모두 삭제
TRUNCATE : 구조 유지 (데이터만 삭제)
DELETE : 원하는 데이터만 삭제 , 복구가능 , 용량이 줄지않고 느림
트랜젝션 특성
원자성 : 트랜젝션에서 연산자들이 모두 성공하거나 모두 실패해야함 (계좌이체 )
일관성 : 트랜젝션 실행 전 DB 내용이 잘못 되지 않으면 실행 후도 잘못 되지 않아야함
고립성 : 트랜잭션 실행도중 다른 트랜잭션의 영향을 받으면 안된다.
지속성 : 트랜잭션이 성공적으로 수행되면 DB 의 내용은 영구적 저장
그룹 내 행 순서 함수
FIRST_VALUE - 가장 먼저 나온 값, MIN 함수와 같다
LAST_VALUE - 가장 나중에 나온 값, MAX 함수와 같다
LAG : 이전 값
- LAG(SAL, 2, 0)
첫번째 : 대상 컬럼명
두번째 : 몇 번째 이전 행을 가져올 건지 결정(DEFAULT는 1)
세번째 : NULL의 경우 다른 값으로 바꿔준다(NVL, ISNULL과 같음)
LEAD : 다음 값
- LEAD(SAL, 2, 0)
첫번째 : 대상 컬럼명
두번째 : 몇 번째 다음 행을 가져올 건지 결정(DEFAULT는 1)
세번째 : NULL의 경우 다른 값으로 바꿔준다(NVL, ISNULL과 같음)
RATIO_TO_REPORT - 파티션 내 전체 SUM()값에 대한 행별 칼럼 값의 백분율을 소수점으로 구한다.
PERCENT_RANK - 먼저나오는것을 0, 가장 나중에 나오는 것을 1로 하여 값이 아닌 행의 순서별 백분율을 구한다.
CUME_DIST - 파티션별 윈도우의 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 구한다.
NTILE - 파티션별 전체 건수를 ARGUMENT 값으로 N등분한 결과를 구한다.(예: 수능등급)
'개발 공부 > DataBase' 카테고리의 다른 글
| DB Lock (0) | 2024.12.18 |
|---|---|
| 트랜잭션 (Transaction) (0) | 2024.12.08 |
| RDB 인덱스 개념 정리 (2) | 2024.12.02 |
| SQL vs NoSQL (3) | 2024.11.15 |

